A Shifting Competitive Landscape
The long-held belief in an unassailable American lead in artificial intelligence is crumbling under the weight of new data. Stanford University’s comprehensive 2026 AI Index Report, a 423-page annual tome from its Institute for Human-Centered Artificial Intelligence, delivers this and other sobering assessments. While headlines often chase raw performance metrics, the report’s most critical insights lie in the neglected chapters on safety and responsibility, where a dangerous divergence is accelerating.
The Vanishing Performance Gap
Let’s address the geopolitical elephant in the server room first. The narrative of permanent U.S. dominance in AI model capability is no longer tenable. According to the index, U.S. and Chinese models have been swapping the top performance spot since early 2025. By March 2026, the lead held by Anthropic’s best model over its closest Chinese rival was a razor-thin 2.7%.
This doesn’t mean the U.S. has lost its innovative edge entirely. America still produced 50 top-tier models in 2025 compared to China’s 30, and its patents pack a heavier punch. However, China now leads in sheer publication volume, citation share, and the number of patents granted. Its presence among the top 100 most-cited AI papers grew significantly from 2021 to 2024. Meanwhile, South Korea quietly leads the world in AI patents per capita. The practical takeaway? The performance gap is now a narrow, fluctuating margin that changes with every major model release.
A Foundational Vulnerability
Beneath this competitive tension lies a stark structural weakness. The United States operates over 5,400 data centers, more than ten times any other nation. Yet the most advanced chips powering those centers almost universally come from a single company: Taiwan Semiconductor Manufacturing Company (TSMC). The entire global AI hardware supply chain funnels through one geopolitical flashpoint, a risk only partially mitigated by TSMC’s new U.S. fab that opened in 2025.
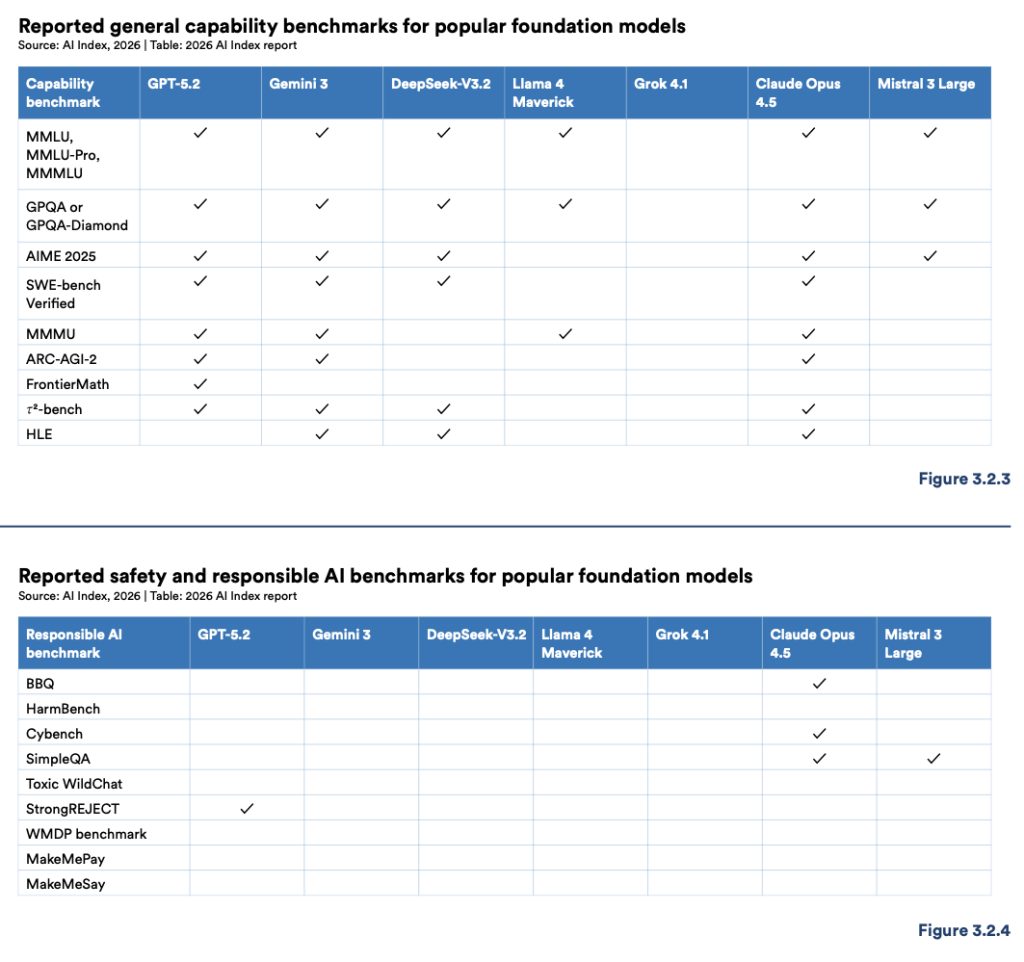
The Glaring Benchmark Void
Here is where the report’s findings become truly unsettling. While every frontier AI lab eagerly publishes results on standard capability benchmarks, they are largely silent on responsible AI metrics. The report’s detailed benchmark tables for safety, fairness, and security are riddled with empty cells. Only Claude Opus 4.5 reported results on more than two of the tracked responsible AI benchmarks. Only GPT-5.2 reported a result for the critical StrongREJECT safety test.
This silence doesn’t imply a total absence of internal safety work. The report acknowledges red-teaming and alignment testing do occur behind closed doors. The problem is a lack of disclosure using common, externally comparable benchmarks. Consequently, comparing the safety profiles of different models is nearly impossible for researchers, regulators, and the public. We’re buying powerful engines without seeing the crash test ratings.
The Rising Tide of Incidents
The consequences of this opacity are becoming measurable. Documented AI incidents rose to 362 in 2025, up sharply from 233 the previous year. The OECD’s automated monitoring system recorded a peak of 435 incidents in a single month in early 2026. Organizations are feeling the strain. The share of companies rating their own AI incident response as “excellent” plummeted from 28% to 18% between 2024 and 2025, while those experiencing multiple incidents grew substantially.
The Intractable Trade-Off Problem
Compounding the challenge is a fundamental technical dilemma. Improving AI safety can inadvertently degrade its accuracy. Enhancing privacy protections might reduce fairness. The field lacks any established framework for managing these complex trade-offs. In crucial areas like fairness and explainability, we don’t even have the standardized longitudinal data needed to track progress, or regress, over time. How do you solve a puzzle when the pieces keep changing shape?
Public Ambivalence Deepens
Global public sentiment mirrors this technical confusion. A growing majority, 59%, believe AI’s benefits outweigh its drawbacks. Simultaneously, a growing majority, 52%, say AI products make them nervous. Both figures are rising in tandem. People are using AI more while becoming less certain about where it’s taking them. This cognitive dissonance is the defining public mood: hopeful adoption paired with deepening anxiety.
What Comes After the Race?
The report paints a clear picture of a field at a crossroads. The sprint for raw capability has created a pack of front-runners separated by microseconds. Yet the marathon for building trustworthy, safe, and governable AI has barely begun, and many front-runners haven’t even laced up their shoes for that longer journey. The next phase of AI development won’t be won by who builds the fastest model, but by who builds the most reliable one. The real test is whether the industry can shift its gaze from the finish line of a benchmark to the horizon of long-term societal integration before the safety gap becomes a chasm.












